
Introduction to Stackery
Stackery is software that helps teams to quickly build and manage serverless infrastructure. In order to fully utilize Stackery's toolset, it's helpful to know a little about serverless app architecture and how it compares to other types of architectures and server management.
This guide is written for serverless beginners. If you're already familiar with building serverless applications, feel free to skip right to our Quickstart Tutorial, which will familiarize you with using Stackery by creating and deploying a serverless web app.
What is Serverless?
Serverless is a form of cloud computing architecture in which the cloud provider manages computing resources, including individual servers.
Yes, there are still servers behind serverless functions, just as “the cloud” consists of a lot of individual servers. As the saying goes, “There is no cloud, it’s just someone else’s computer”. This is true for serverless as well. We could just as well say, “There is no serverless, it’s just someone else’s problem.”
These are five general characteristics that classify cloud services as serverless:
- No management of servers (including virtual machines or containers): the cloud provider does this for you
- Pricing based on consumption, not capacity: you pay for resources only when they’re in use
- Scaling built in: a resource or application scales to meet demand
- Automatic availability and fault tolerance: more things you don’t have to worry about
- Provisioning resources through infrastructure-as-code, not hardware

Serverless development
Developing serverless applications requires a change of mindset for seasoned engineers who are used to writing monolithic applications or microservices. While serverless development allows engineers to develop and deploy applications faster than in previous workflows, there are some DevOps challenges to undertake. The most significant adjustment is often in a developer's environment, since you can't run managed cloud services on your local development laptop.
With serverless, deploying to the cloud becomes part of the development process. Engineers need to deploy as part of their daily workflow of developing and testing functionality. Automated testing generally needs to happen against a deployed environment, where the managed service integrations can be fully exercised and validated.
This means the environment management needs of a serverless team shift significantly. You need to get good at managing a multitude of AWS accounts and developer specific environments, avoiding namespace collisions and injecting environment-specific configuration.
In short, serverless development requires new workflows and toolsets; Stackery is one of the toolsets that can help serverless teams thrive.
Types of serverless stacks
Serverless applications have three components:
- Business logic: a function (Lambda) that defines the logic of the application
- Building blocks: Resources such as databases, API gateways, authentication services, IOT, Machine Learning, container tasks, and other cloud services that support a function
- Workflow phase dependencies: Environment configuration and secrets that respectively define and enable access to the dependencies unique to each phase of the development workflow
Taken together, these three components create a single “stack” that is “deployed”: i.e., activated within a specified AWS account and region. In some applications, they can make up the entire backend.
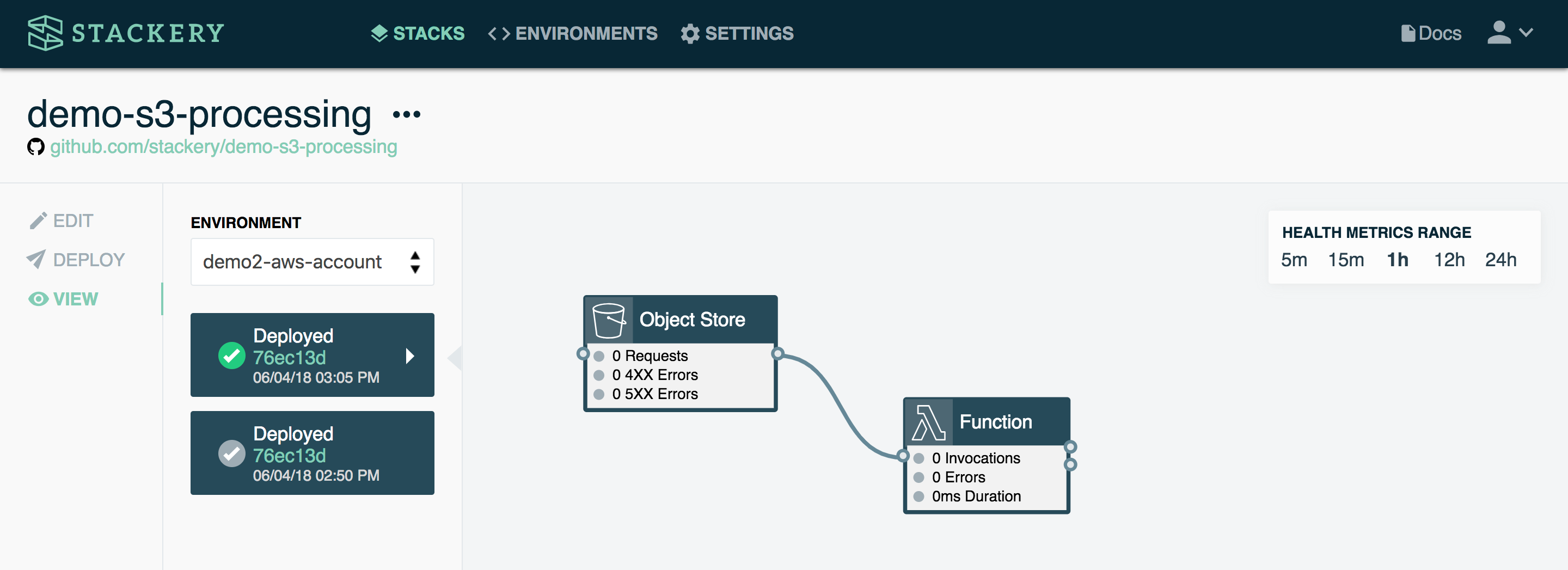
The above example is about as simple as you can get with a stack. It consists of a function and an object store. When triggered, the function manipulates the data stored in the object store (in this case, an S3 bucket on AWS).
A simple use case would be a function that returns a specific image from the bucket when triggered. For instance, when a user logs into an app, their profile picture could be retrieved from the object store.
Here’s a somewhat more complex stack:
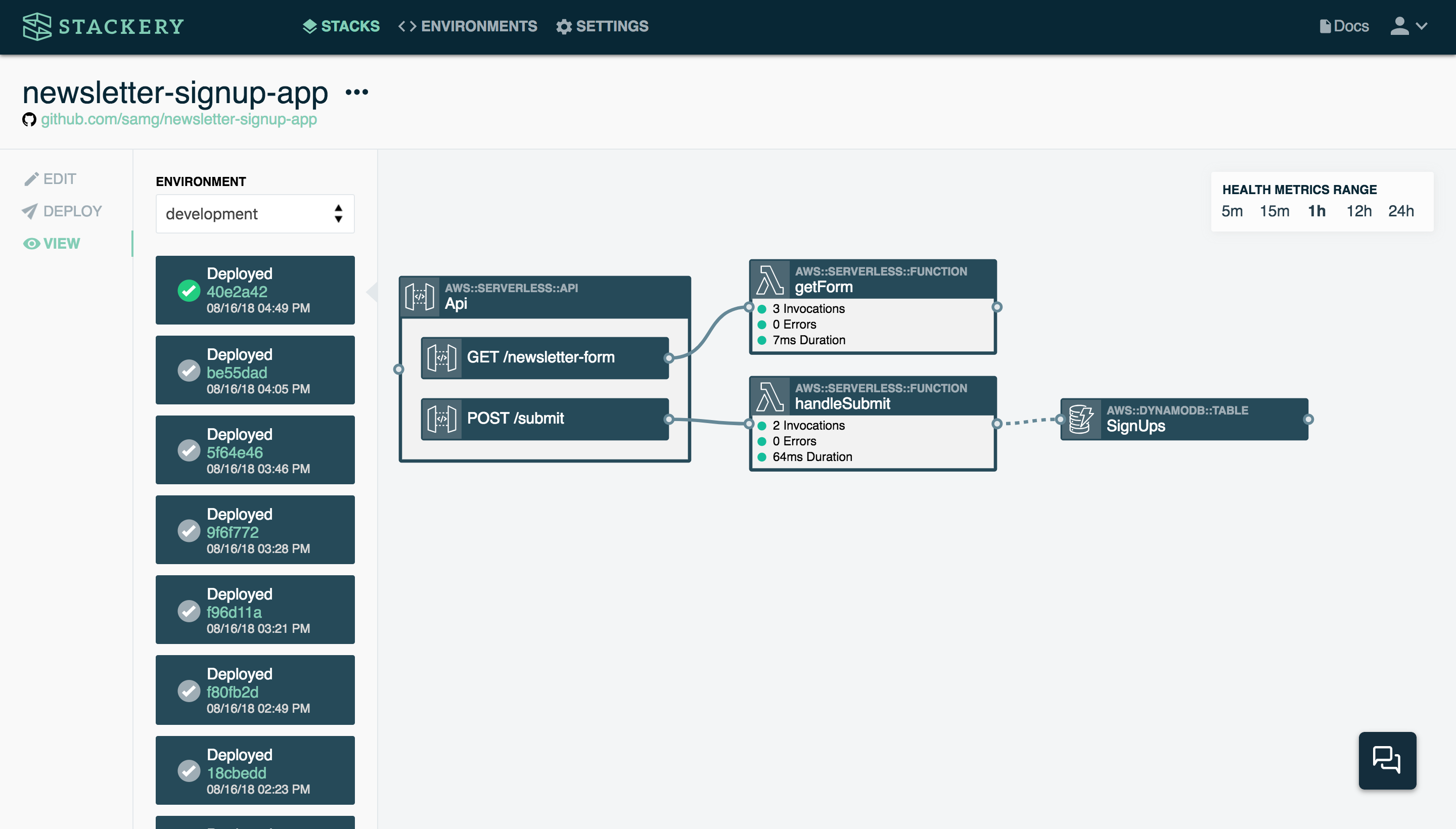
This stack consists of a function (handleSubmit) that is triggered when someone submits an email address on a website’s newsletter signup form (POST /submit in the API). The function takes the contents of that signup form (in this case, a name and email address) and stores it in a table called SignUps. If this stack were to be expanded, another function could email the contents of the SignUps table to a user when requested, for example.
Under the hood, this stack is using several AWS services: Lambda for the functions, API Gateway for the API, and DynamoDB for the table.
Here is a stack handling CRUD operations in a web application:
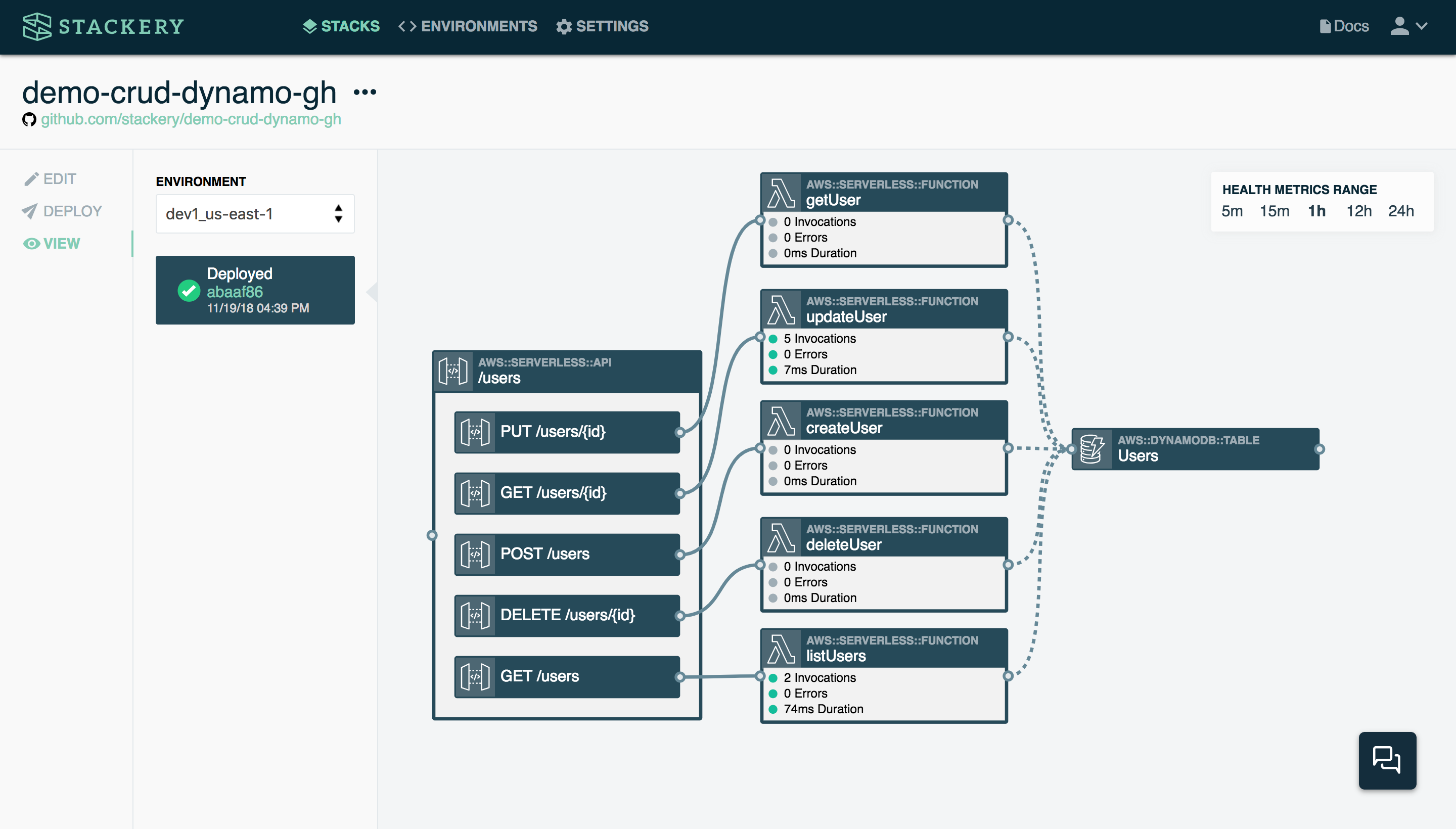
While this looks like a complex operation, it’s actually just the GET, PUT, POST, and DELETE methods connected to a table of users. Each of the functions is handling just one operation, depending on which API endpoint is triggered, and then the results of that function are stored in a table.
This kind of CRUD stack would be very useful in a web application that requires users to sign up and sign in to use. When a user signs up, the POST API triggers the createUser function, which simply pulls up the correct DynamoDB table and writes the values sent (typically username and password) to the table. The next time the user comes back to the app and wants to log in, the getUser function is called by the GET API. Should the user change their mind and want to delete their account, the deleteUser function handles that through the DELETE API.
Finally, let's look at a complex, real-world situation:
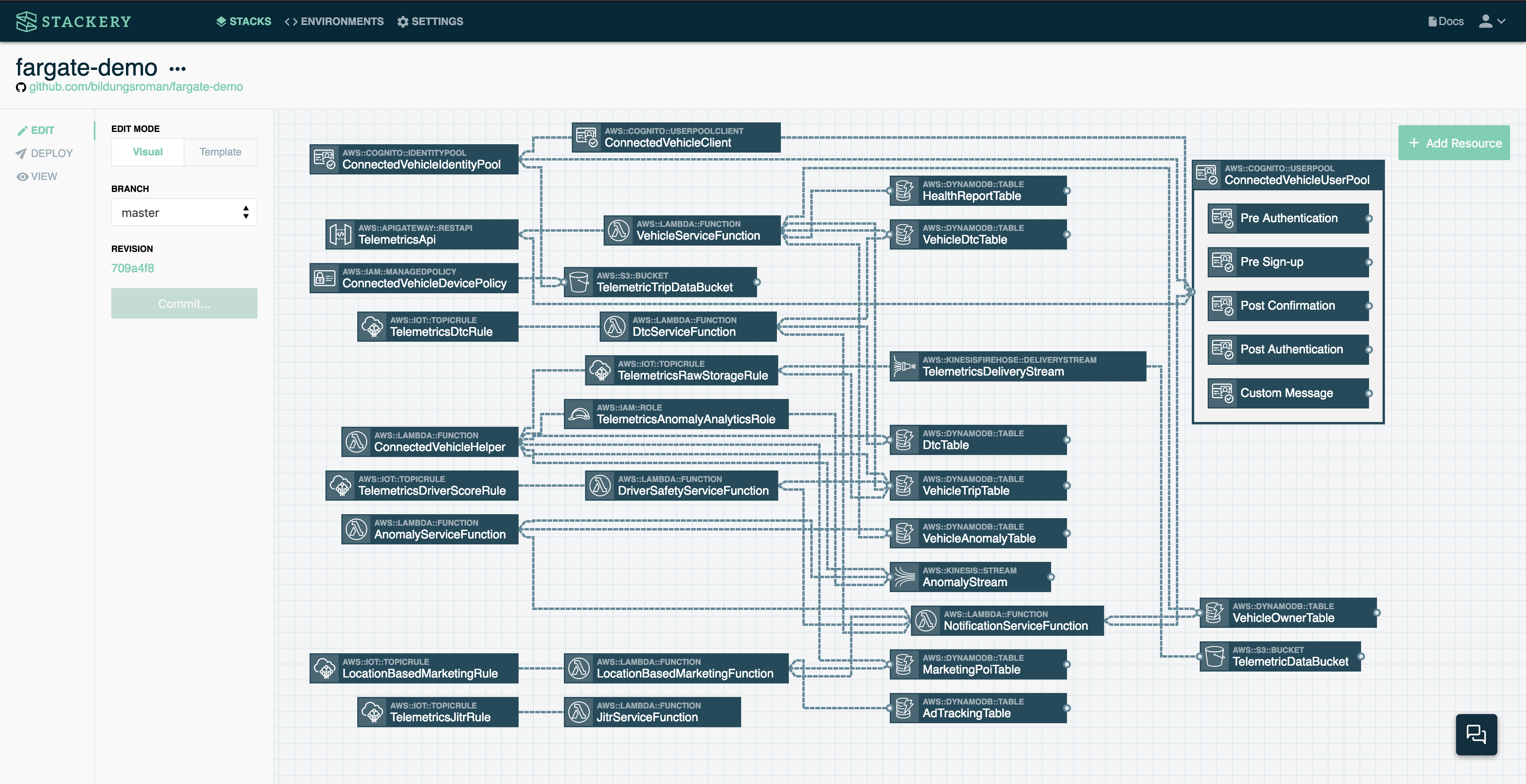
This is an actual AWS CloudFormation template for deployment of the AWS Connected Vehicle Solution. We won't get into the details, but at over 2400 lines of YAML, this is an advanced use case of serverless, though by no means unusual in production applications.
Serverless templates
A serverless stack is described by a template file, typically written in YAML or JSON. This configuration file describes the functions, API endpoints and other resources in your application.
The Serverless Application Model (SAM)
Stackery is built to utilize AWS's open-source Serverless Application Model (AWS SAM) template.
Stackery does support other template formats, which you can read about in our serverless template formats documentation.
A SAM template is the blueprint for your serverless application, describing all of your resources and the relationships between them. Here's an example of a SAM template for the newsletter signup stack shown above:
AWSTemplateFormatVersion: 2010-09-09
Transform: AWS::Serverless-2016-10-31
Description: Stackery Serverless CRUD API Demo
Resources:
function48A53742:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub ${AWS::StackName}-function48A53742
Description: !Sub
- Stackery Stack ${StackeryStackTagName} Environment ${StackeryEnvironmentTagName} Function ${ResourceName}
- ResourceName: listUsers
CodeUri: src/function48A53742
Handler: index.handler
Runtime: nodejs12.x
MemorySize: 3008
Timeout: 30
Tracing: Active
Policies:
- AWSXrayWriteOnlyAccess
- DynamoDBCrudPolicy:
TableName: !Ref table6E08C5D
Environment:
Variables:
TABLE_NAME: !Ref table6E08C5D
TABLE_ARN: !GetAtt table6E08C5D.Arn
Events:
api3FEE112A:
Type: Api
Properties:
Path: /users
Method: GET
RestApiId: !Ref api3FEE112A
Metadata:
StackeryName: listUsers
api3FEE112A:
Type: AWS::Serverless::Api
Properties:
Name: !Sub
- ${ResourceName} From Stackery Stack ${StackeryStackTagName} Environment ${StackeryEnvironmentTagName}
- ResourceName: /users
StageName: !Ref StackeryEnvironmentAPIGatewayStageName
DefinitionBody:
swagger: '2.0'
info: {}
paths:
/users:
get:
x-amazon-apigateway-integration:
httpMethod: POST
type: aws_proxy
uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${function48A53742.Arn}/invocations
responses: {}
post:
x-amazon-apigateway-integration:
httpMethod: POST
type: aws_proxy
uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${function1D0BF340.Arn}/invocations
responses: {}
/users/{id}:
get:
x-amazon-apigateway-integration:
httpMethod: POST
type: aws_proxy
uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${functionC2148022.Arn}/invocations
responses: {}
put:
x-amazon-apigateway-integration:
httpMethod: POST
type: aws_proxy
uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${function6871BEC5.Arn}/invocations
responses: {}
delete:
x-amazon-apigateway-integration:
httpMethod: POST
type: aws_proxy
uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${function5A53E646.Arn}/invocations
responses: {}
EndpointConfiguration: REGIONAL
Metadata:
StackeryName: /users
function5A53E646:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub ${AWS::StackName}-function5A53E646
Description: !Sub
- Stackery Stack ${StackeryStackTagName} Environment ${StackeryEnvironmentTagName} Function ${ResourceName}
- ResourceName: deleteUser
CodeUri: src/function5A53E646
Handler: index.handler
Runtime: nodejs12.x
MemorySize: 3008
Timeout: 30
Tracing: Active
Policies:
- AWSXrayWriteOnlyAccess
- DynamoDBCrudPolicy:
TableName: !Ref table6E08C5D
Environment:
Variables:
TABLE_NAME: !Ref table6E08C5D
TABLE_ARN: !GetAtt table6E08C5D.Arn
Events:
api3FEE112A:
Type: Api
Properties:
Path: /users/{id}
Method: DELETE
RestApiId: !Ref api3FEE112A
Metadata:
StackeryName: deleteUser
function1D0BF340:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub ${AWS::StackName}-function1D0BF340
Description: !Sub
- Stackery Stack ${StackeryStackTagName} Environment ${StackeryEnvironmentTagName} Function ${ResourceName}
- ResourceName: createUser
CodeUri: src/function1D0BF340
Handler: index.handler
Runtime: nodejs12.x
MemorySize: 3008
Timeout: 30
Tracing: Active
Policies:
- AWSXrayWriteOnlyAccess
- DynamoDBCrudPolicy:
TableName: !Ref table6E08C5D
Environment:
Variables:
TABLE_NAME: !Ref table6E08C5D
TABLE_ARN: !GetAtt table6E08C5D.Arn
Events:
api3FEE112A:
Type: Api
Properties:
Path: /users
Method: POST
RestApiId: !Ref api3FEE112A
Metadata:
StackeryName: createUser
functionC2148022:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub ${AWS::StackName}-functionC2148022
Description: !Sub
- Stackery Stack ${StackeryStackTagName} Environment ${StackeryEnvironmentTagName} Function ${ResourceName}
- ResourceName: updateUser
CodeUri: src/functionC2148022
Handler: index.handler
Runtime: nodejs12.x
MemorySize: 3008
Timeout: 30
Tracing: Active
Policies:
- AWSXrayWriteOnlyAccess
- DynamoDBCrudPolicy:
TableName: !Ref table6E08C5D
Environment:
Variables:
TABLE_NAME: !Ref table6E08C5D
TABLE_ARN: !GetAtt table6E08C5D.Arn
Events:
api3FEE112A:
Type: Api
Properties:
Path: /users/{id}
Method: GET
RestApiId: !Ref api3FEE112A
Metadata:
StackeryName: updateUser
function6871BEC5:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub ${AWS::StackName}-function6871BEC5
Description: !Sub
- Stackery Stack ${StackeryStackTagName} Environment ${StackeryEnvironmentTagName} Function ${ResourceName}
- ResourceName: getUser
CodeUri: src/function6871BEC5
Handler: index.handler
Runtime: nodejs12.x
MemorySize: 3008
Timeout: 30
Tracing: Active
Policies:
- AWSXrayWriteOnlyAccess
- DynamoDBCrudPolicy:
TableName: !Ref table6E08C5D
Environment:
Variables:
TABLE_NAME: !Ref table6E08C5D
TABLE_ARN: !GetAtt table6E08C5D.Arn
Events:
api3FEE112A:
Type: Api
Properties:
Path: /users/{id}
Method: PUT
RestApiId: !Ref api3FEE112A
Metadata:
StackeryName: getUser
table6E08C5D:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
StreamSpecification:
StreamViewType: NEW_AND_OLD_IMAGES
TableName: !Sub ${AWS::StackName}-table6E08C5D
Metadata:
StackeryName: Users
Parameters:
StackeryStackTagName:
Type: String
Description: Stack Name (injected by Stackery at deployment time)
StackeryEnvironmentTagName:
Type: String
Description: Environment Name (injected by Stackery at deployment time)
StackeryEnvironmentAPIGatewayStageName:
Type: String
Description: Environment name used for API Gateway Stage names (injected by Stackery at deployment time)
You can view the entire GitHub repository of a newsletter signup application to get a better sense of what a serverless application looks like.
Users building a serverless application from scratch would need to write their own template.yaml file as part of the application development process. One of the advantages of using Stackery is that this file is automatically configured as you add resources in the Stackery Dashboard or the CLI.
What is Stackery?
Stackery is serverless acceleration software, a set of development and operations tools for engineers building production serverless applications. It consists of a web-based Dashboard and a command line (CLI) tool, as well as the Stackery Role, which is a group of resources allowing Stackery to be linked with the user's AWS account(s).
These tools are used to manage production serverless applications throughout their lifecycle, particularly in the case of a team workflow, where different developers can have different permissions sets, environments, and other configurations.
Stackery terms
Stacks
As defined above, stacks in Stackery are individual applications consisting of interactions between cloud resources specified in a configuration file (in the form of a template.yaml or serverless.yaml file located in the root directory of the stack’s repository). To see all of your stacks, just click the Stacks link in the main navigation.
In Stackery, the stack code and configuration is stored in a Git repository from your usual Git provider such as GitHub, which means your typical application workflow of commits and PRs is preserved when working within the app.
Cloud Resource References

A Cloud Resource Reference represents an AWS service within a stack. These resources are shown as boxes in the Stackery Dashboard. They come in a variety of types that represent various cloud provider resources such as AWS Lambda functions, API services (API Gateway or AppSync for GraphQL), datastores (e.g. S3, MySQL, Postgres, DynamoDB), network infrastructure (e.g. Virtual Networks, CDNs), and Docker Tasks. Some reference types have input and output ports that are used in combination with Wires to subscribe to and publish events. A full list of Cloud Resource Reference types can be found in the menu to the left.
Environments
Environments provide a mechanism to store environment-specific configuration values such as database passwords, API keys, or application configurations, as well as deployment configurations (by region and AWS account). It’s typical to have a set of environments such as production, staging, and development. In some cases, it’s useful to create individual development environments for each engineer. When an environment is created within Stackery, you specify a region and an AWS account. Stacks will be deployed into the AWS account and region associated with the environment.
Read more about environments in our Environments documentation, as well as secrets management in our Environment Secrets documentation.
Resource Integration
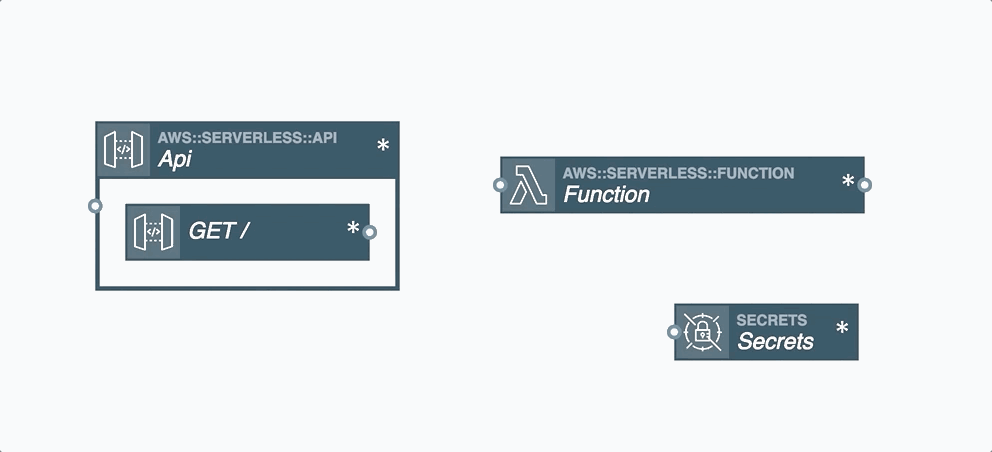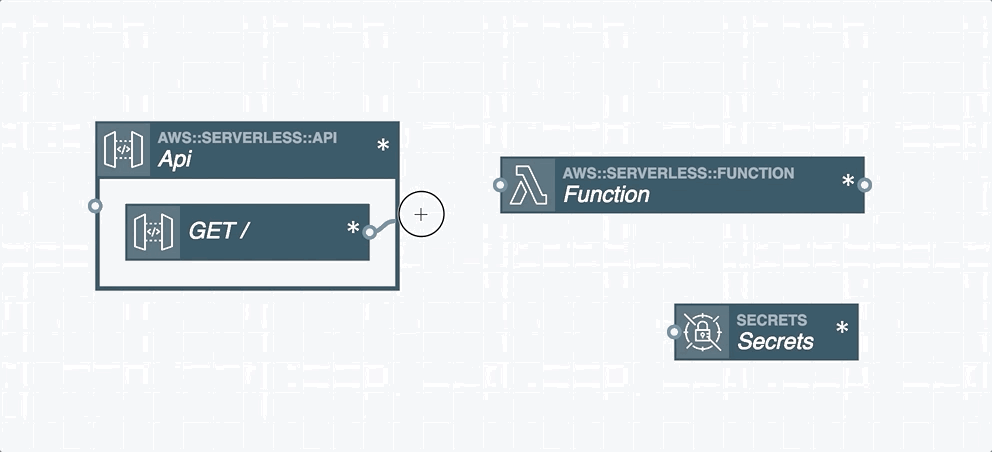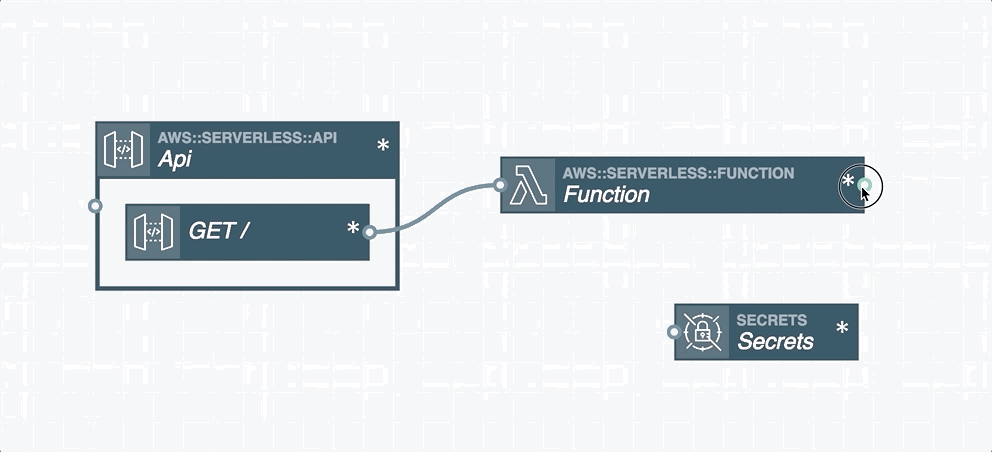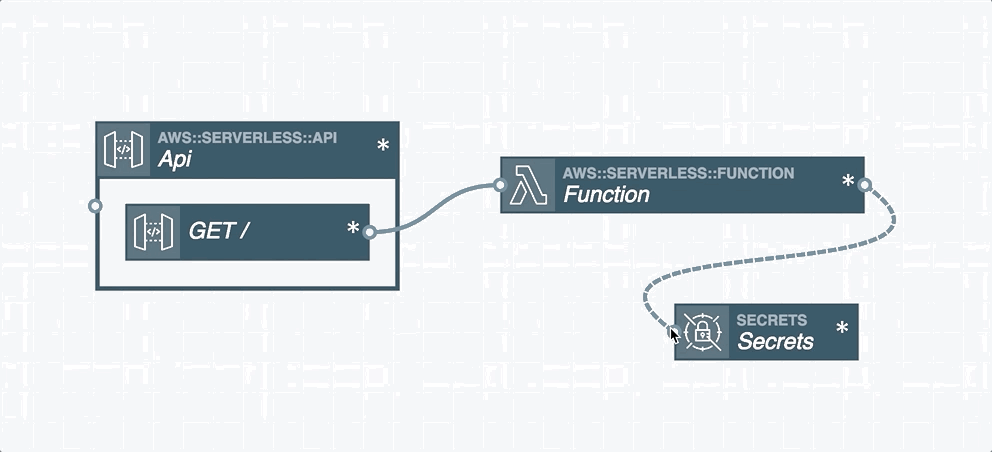
In serverless applications, certain cloud resources must integrate with one another. A resource integration is a connection between two resources and is represented by a wire between them in the Stackery Dashboard. You'll find two types of wires in the Stackery Dashboard:
Event Subscription Wire: a solid line shown that represents an event subscription or integration between Cloud Resources.
Service Discovery Wire: a dashed line shown that connects a Compute Resource (Function or Docker Task) to another Cloud Resource Node. A Service Discovery Wire can only originate from a Compute Resource and populates the IAM permissions and environment variables required for it to perform actions on the connected resource.
Wires are used to subscribe one resource to an event stream emitted by another resource. For example, a Function's input is commonly connected to a Rest API's output, which subscribes an AWS Lambda function to API Gateway HTTP events. This pattern can be used to subscribe Lambda functions to a wide variety of event sources such as S3, DynamoDB, API Gateway, GraphQL API through AppSync, Kinesis streams, CloudWatch Events, other Lambda functions, and unhandled exceptions.
Learn more
To learn more about each element of Stackery's software, see the documentation under the "Using Stackery" section to the left, or dive right in with the Quickstart.