
Function
Resource Overview
A Function represents an AWS Lambda function. AWS Lambda allows you to author and run custom code without having to worry about provisioning and managing servers. By using Lambda functions in your applications, you're taking advantage of the resilient compute resources that AWS offers, constructing an event driven application flow, and possibly reducing costs with invocation based billing.
Key Features of AWS Lambda include:
- Zero administration; AWS manages the underlying compute resources on your behalf
- Ability to add custom logic to other AWS services
- Pricing is pay per use, which means you pay only for the compute time that's required to run your code
- Built in fault tolerance and automatic scaling
- Currently supports Node.js, Java, C#, Go, and Python
A Function consists of your Lambda code, required dependencies, an event trigger, and a desired output. When configuring a Function, you declare resource names and a source path to help with source code and workflow management. You define the runtime version, memory size, maximum execution time, and the amount of concurrent executions. See the Configuring Lambda Functions documentation for a complete discussion of these elements.
With these properties declared, and your Function created, it's time to add your custom code, event triggers, and desired outputs to fit the requirements of your serverless applications. Be sure to work in these best practices to ensure you're getting the most out of your function.
Event Subscription
Event subscription wires (solid line) visualize and configure event subscription integrations between two resources.
Functions can subscribe to events emitted from the following resources:
- GraphQL API Resolver
- Job Queue
- Object Store
- PubSub Topic
- HTTP API
- REST API
- Stream
- Table
- Timer
- User Pool
Functions do not emit events but they can be programmed to invoke other Functions.
Service Discovery
A Function is considered a Compute Resource; it adopts the permissions and environment variables required to perform actions using cloud resources within the stack. This occurs when a service discovery wire (dashed line) is connected from this resource to another cloud resource.
Functions are capable of environment aware service discovery and permission scoping for the following resources:
- Function
- Docker Task
- GraphQL API
- Job Queue
- Object Store
- PubSub Topic
- HTTP API
- REST API
- Stream
- Table
- Timer
- Secrets
- User Pool
- Virtual Network (resources within a Virtual Network)
Configurable Properties
Display Name
Human readable name for this resource that is displayed on the Stackery Dashboard and Stackery CLI output.
Logical ID
The unique identifier used to reference this resource in the stack template. Defining a custom Logical ID is recommended, as it allows you to quickly identify a resource and any associated sub-resources when working with your stack in AWS, or anywhere outside of the Stackery Dashboard. As a project grows, it becomes useful in quickly spotting this resource in template.yaml or while viewing a stack in Template View mode.
The Logical ID of all sub-resources associated with this Function will be prefixed with this value.
The identifier you provide must only contain alphanumeric characters (A-Za-z0-9) and be unique within the stack.
Default Logical ID Example: Function2
IMPORTANT : AWS uses the Logical ID of each resource to coordinate and apply updates to the stack when deployed. On any update of a resource's logical ID (or any modification that results in one), CloudFormation will delete the currently deployed resource and create a new one in it's place when the updated stack is deployed.
Runtime
Functions currently support the following runtime versions:
- Node.js - 12.x, 10.x
- Node.js (Typescript) - Node.js 12.x and 10.x with Typescript
- Python - Python 3.8, 3.7, 3.6 and 2.7
- Java - Java 11 and Java 8
- .NET - .NET Core 3.1, 2.1
- Ruby - Ruby 2.5
- Go - Go 1.x
- Provided - Runtime provided with AWS Lambda Layers
Node.js can come in a Typescript flavor. Selecting nodejs12.x (typescript) or nodejs10.x (typescript) as a runtime will scaffold index.ts and tsconfig.json files as well as Typescript-specific dependencies in the function's package.json.
Note that Typescript functions need to be transpiled to Node.js before deploying. This can be easily done by creating a file called stackery.prebuild.sh in the stack's deployHooks directory with the following:
#!/bin/bash
for i in src/*; do echo transpiling $i function; (cd $i; npm install; npm run build); done
(In local edit mode, this is done for you).
When running stackery local invoke for a Typescript function, be sure to use the --build flag so the function is transpiled using the above deploy hook before it's invoked.
Source Path
You can designate a specific path within the repository that houses the function's source code. Functions are given an auto-generated name and stored within the 'src' folder by default.
Handler
The handler serves as the Function's entry point; the method that is executed when the function is invoked.
Default Handler Names
- Node.js - index.js
- Python - handler.py
- Java - Handler.java
- .NET - Handler.cs
- Ruby - function.rb
- Go - Handler.cs
- Provided Runtime - Handler name will vary
If a custom runtime is provided using Layers, you must ensure that the correct handler name is defined
Layers
Provide the ARN of the AWS Lambda Layer for the Function to use. See the Source Code section below to learn more about Layers.
Memory
The amount of memory allocated to the function process, ranging from 128 MB to 3008 MB.
CPU increases in proportion to the Function's memory size to enable faster initialization.
Timeout
The maximum amount of time the function can spend executing, ranging from 1 to 900 seconds (15 minutes). An error will occur if the timeout is reached before the function completes execution.
Provision Concurrency
When enabled, users can pre-provision execution environments, ensuring that a number of simultaneous requests may be served with low latency. Application auto-scaling is used create or destroy execution environments in order to keep utilization near the target, bounded by the given minimum and maximum values.
The options for Provision Concurrency include:
- Minimum number of pre-provisioned concurrent invocations
- Maximum number of pre-provisioned concurrent invocations
- Autoscale concurrency utilization
Reserve Concurrency
When enabled, users can specify and reserve a bounded number of concurrent function executions. This option ensures a function can always reach a certain level of concurrency but also limits the maximum concurrency for the function. Reserved concurrency applies to function versions and aliases. As the function scales and new instances are allocated, the runtime loads the function code and runs any associated initialization code. Depending on the size of the function's code and dependencies, this process can take some time and result in higher latency. To avoid any fluctuations in latency, consider enabled Provisioned Concurrency on your functions.
Permissions
SAM or IAM permission policies which grant your Function permission to perform actions on other Cloud Resources. Function permissions are automatically populated when you connect a service discovery wire (dashed wire) from a Function to another Cloud Resource. You also have the ability to manually define these permissions that your Function requires.
Environment Variables
Environment variables are key-value pairs that enable users to define variables in the runtime environment that will dynamically populate in your Function. Function environment variables are automatically populated when you connect a service discovery wire (dashed wire) from a Function to another Cloud Resource. You also have the ability to manually define these environment variables that your Function requires.
Environment Variables are key-value pairs that can be used within the Function code. These environment variables are dynamically populated at runtime. A Function's environment variables can be defined in two ways:
- User provides the key-value pair to use as a literal, YAML, or config (values stored in the Stack's current environment parameters) value.
- Connecting a service discovery wire (dashed wire) from this Function to another cloud resource.
Trigger on First Deploy
Enable this feature to trigger this Function only on your initial stack deployment. An example of this could be using a Function to seed initial data into a Database or Table.
Your Function must correctly respond to CloudFormation Custom Resource events. For more details refer to AWS CloudFormation Custom Resource Docs.
Trigger on Every Deploy
Enable this feature to trigger this Function on every stack deployment. An example of this could be having a single page application stored with the Function responsible for deploying it. Any changes to the application code will be redeployed on every stack deployment.
Your Function must correctly respond to CloudFormation Custom Resource events. For more details refer to AWS CloudFormation Custom Resource Docs.
Use Existing Lambda Function
When enabled, this feature provides you with a field to specify the Amazon Resource Name (ARN) of an existing Lambda Function to reference in your application.
When working with existing Lambda Functions:
Stackery allows
- Connecting a Function or Docker Task resource in the stack to a Lambda Function that exists outside of the current stack
Stackery does NOT allow
- Subscribing an existing Lambda Function (outside of the current stack) to an event source resource within the stack
- Modifying an existing Lambda Function (outside of the current stack) by connecting them to other resources within the stack
You may reference an environment parameter in order to conditionally reference existing infrastructure based on environment.
Source Code
Accessing your Source Code
In the Git repository for your stack, your source code can be located at the source path you defined within your Function's configurable properties. By default, your source path for your Function will be something like src/functionABC123. Inside this folder you'll find the files that make up your Function's documentation, custom code, and any required dependencies.
- README.md file for your Function's documentation
- Handler function to serve as your Function's executable code, or entry point for other files (file name varies by runtime language)
- Dependencies file that defines required files or packages for your code to run (file name varies by runtime language)
Work in these best practices to ensure you're getting the most out of your function.
Using Environment Variables
In order for you to reference the environment variables defined in your Function's properties, use the following variable calls. Environment variable calls in your Function vary by runtime language and need to be added wherever they are required by the SDK.
- Node.js -
process.env.myVariableName - Python -
os.environ['myVariableName'](import osrequired) - Java -
System.getenv("myVariableName") - .NET Core -
Environment.GetEnvironmentVariable("myVariableName") - Ruby -
ENV["myVariableName"] - Go -
os.Getenv("myVariableName")(import osrequired)
Dependencies
You function's dependencies are installed when the stack is deployed. When working with your function code local dependencies can be added as individual files and package dependencies can be added to each runtime's package management file.
- Node.js -
package.json - Python -
requirements.txt - Java -
build.gradle - .NET Core -
Stackery.csproj - Ruby -
Gemfile - Go -
Makefile(requiresdeployHooks/stackery-build.shto deploy)
Layers
AWS Lambda Layers are ZIP archives that can contain custom runtimes, libraries, or other dependencies. These layers can be used by your Function without increasing the size of its deployment package, and can be shared across multiple Functions.
A Function can use up to 5 layers at a time, one of them capable of being a custom runtime. The Function's unzipped deployment package size, including it's layers, cannot exceed 250 MB.
Due to their reusable nature, consider adding any layer ARN's to the Environment Parameters for the current stack environment. These environment variables can be accessed by selecting Config on the right of the input field.
Begin typing the Environment Parameters key and select the appropriate layer to use when auto-suggestions populate.
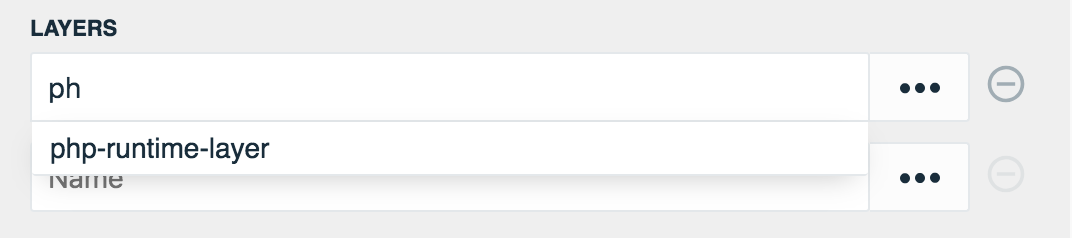
Stackery has contributed a PHP Runtime Layer available for use. Visit the repository to get started, as well as AWS documentation to learn more about creating custom runtimes for your Functions.
IAM Permissions
When connected by a service discovery wire (dashed wire), a Function or Docker Task will add the following IAM statement/policy to its role and gain permission to access this resource.
AWSXrayWriteOnlyAccess
Grants a Function or Docker Task permission to write to AWS X Ray for tracing.
LambdaInvokePolicy
Grants a Function or Docker Task permission to invoke a Function resource within the stack or an existing Lambda function outside of the current stack.
Environment Variables
When connected by a service discovery wire (dashed wire), a Function or Docker Task will automatically populate and reference the following environment variables in order to interact with this resource.
FUNCTION_NAME
The Logical ID of the Function resource.
Example: Function2
FUNCTION_ARN
The Amazon Resource Name of the AWS Lambda function.
Example: arn:aws:lambda:us-east-1:576461710493:function:stack-name-Function2
Chaining Functions together using a PubSub Topic can improve performance, latency, and scalability.
AWS SDK Code Example
Language-specific examples of AWS SDK calls using the environment variables discussed above.
Invoke another Function

// Load AWS SDK and create a new Function object
const AWS = require("aws-sdk");
const lambda = new AWS.Lambda();
const functionName = process.env.FUNCTION_NAME; // supplied by Function service-discovery wire
exports.handler = async message => {
const payload = {
source: 'invokeFunction',
content: 'Sample Data'
};
// Construct parameters for the invoke call
const params = {
FunctionName: functionName,
Payload: JSON.stringify(payload)
};
await lambda.invoke(params).promise();
console.log(functionName + ' invoked');
}
import boto3
import os
import json
# Create an Lambda client
lambda_client = boto3.client('lambda')
function_name = os.environ['FUNCTION_NAME'] # Supplied by Function service-discovery wire
def handler(message, context):
params = {
"source": "invokeFunction",
"content": "SampleData"
}
# Invoke another Function
response = lambda_client.invoke(
FunctionName=function_name,
Payload=json.dumps(params)
)
return
Metrics & Logs
Double clicking a resource while viewing your stack's current deployment gives you access to your pre-configured resource properties, and the following metrics and logs.
- Invocation Metrics
- Execution Duration
- Logs
- X-Ray Traces
Related AWS Documentation
AWS Documentation: AWS::Serverless::Function
AWS SDK Documentation: Node.js | Python | Java | .NET | Ruby | Go